L’analisi video basata sull’intelligenza artificiale aiuta gli addetti alla videosorveglianza a svolgere meglio e più velocemente il proprio compito di rilevamento e prevenzione di comportamenti pericolosi, illeciti o sospetti. Come funziona, quali algoritmi utilizza e come si “addestra” per migliorarne l’efficacia?
L’analisi video basata sull’AI (Intelligenza Artificiale) è uno degli elementi chiave della videosorveglianza 2.0: anche se non può, almeno per il momento, sostituirsi all’esperienza dell’uomo e alle sue capacità decisionali, sfrutta le soluzioni AI per aumentare l’efficienza dell’operatore umano e ridurre i margini di errore. Impiega infatti alcune applicazioni per velocizzare l’analisi dei dati e automatizzare le operazioni ripetitive (per esempio, la ricerca delle targhe in un database o l’analisi dei lineamenti di una persona).
A oggi, le analisi AI-based vengono principalmente utilizzate per determinare approssimativamente la rilevanza di un evento prima di avvisare un operatore per decidere come intervenire. Vengono quindi impiegate a fini di scalabilità per consentire al professionista di dedicarsi ad altri compiti più importanti, concentrandosi sugli eventi sospetti.
Machine learning e deep learning: quali differenze?
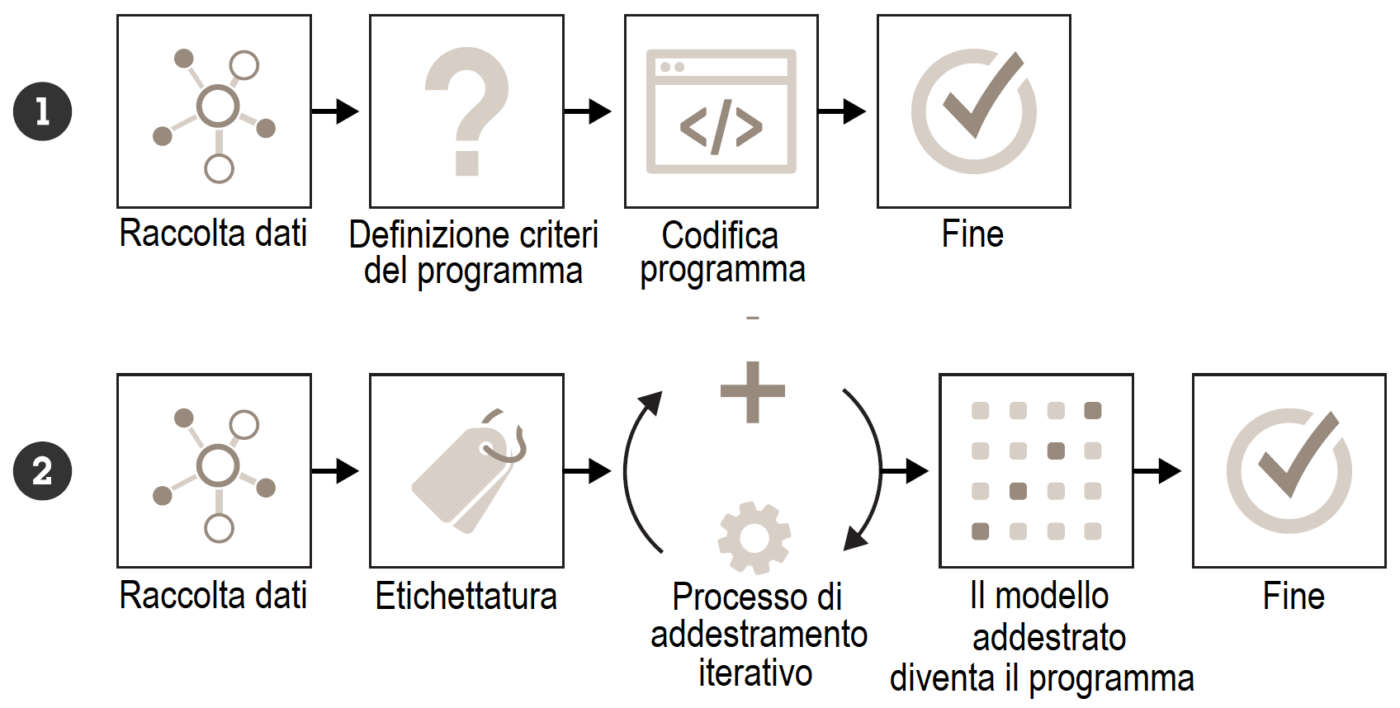
L’intelligenza artificiale è un concetto ampio, associato alle macchine che possono risolvere operazioni complesse dimostrando i tratti tipici dell’intelligenza umana. Un algoritmo AI viene sviluppato mediante un processo iterativo: si ripete un ciclo di raccolta dei dati di addestramento, che vengono etichettati e utilizzati per addestrare e testare l’algoritmo fino a quando non raggiunge il livello qualitativo desiderato; una volta addestrato, l’algoritmo è pronto per essere utilizzato in applicazioni analitiche da acquisire e utilizzare in un sito da sorvegliare.
I due principali sottoinsiemi dell’AI sono il deep learning e il machine learning: entrambi costruiscono automaticamente un modello matematico, che utilizza una gran quantità di dati campione (dati di addestramento) così che il sistema possa imparare a calcolare i risultati senza una specifica programmazione.
Il machine learning impiega algoritmi di apprendimento statistici, così da costruire sistemi capaci di imparare automaticamente e migliorarsi con l’addestramento. Si può utilizzare quando, nell’ambito della videosorveglianza, si parla di visione artificiale, facendo riferimento al processo con cui un computer analizza una scena (video e immagini) in tempo reale oppure registrata.
Con la programmazione tradizionale, è possibile ottenere una visione artificiale basata su metodi che calcolano le caratteristiche dell’immagine, definite manualmente dallo sviluppatore dell’algoritmo; quando si utilizzano invece gli algoritmi di machine learning, le caratteristiche dell’immagine vengono definite manualmente, ma il modo di combinarle viene insegnato all’algoritmo attraverso l’esposizione a grandi quantità di dati di addestramento etichettati (annotati) fino a quando l’applicazione impara a sufficienza per rilevare ciò che si desidera identificare: uno specifico tipo di veicolo (berlina, SUV, station wagon, furgone ecc.) o i lineamenti e le caratteristiche di una persona (altezza, corporatura, abbigliamento, accessori come borse o zaini ecc.).
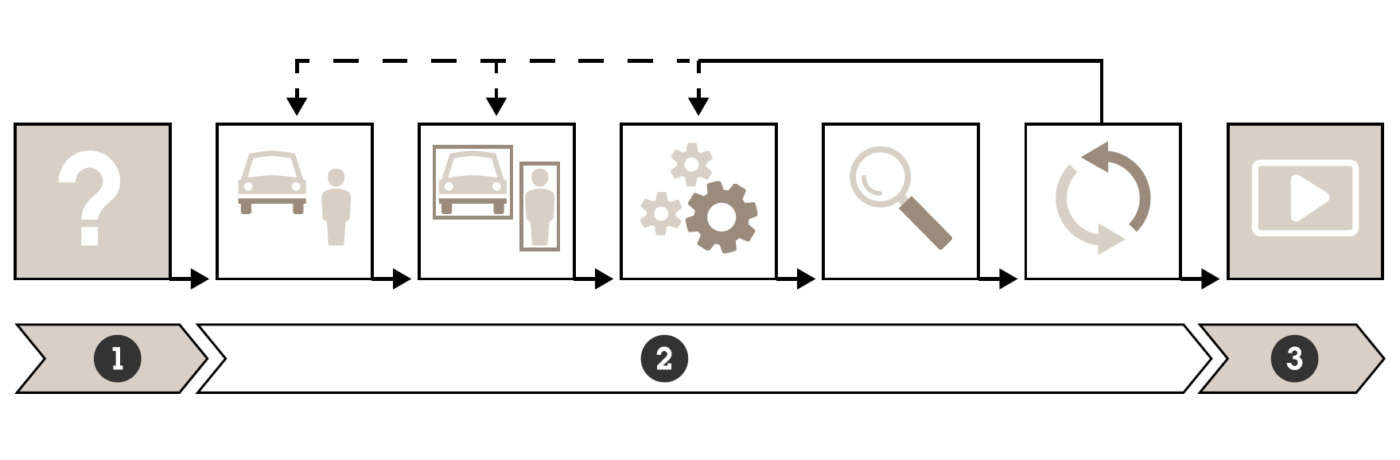
Fonte: Axis Communications
Il deep learning è una versione avanzata del machine learning: sia l’estrazione delle caratteristiche (features), sia la loro combinazione in strutture profonde di regole, finalizzata alla produzione di un output, vengono apprese a partire dai dati. L’algoritmo può definire automaticamente le caratteristiche da cercare nei dati di addestramento e apprendere strutture molto profonde di combinazioni di caratteristiche concatenate. Grazie agli algoritmi di deep learning, è possibile creare rilevatori ottici evoluti e addestrarli automaticamente a individuare oggetti molto complessi, a prescindere da dimensioni, rotazione e altre variazioni. Un rilevamento basato su deep learning può, per esempio, non solo rilevare i veicoli, ma anche classificarli per tipo, marca e modello.
I sistemi di deep learning riescono a imparare da una quantità di dati molto maggiore e variegata rispetto agli algoritmi di machine learning. In molti casi superano di gran lunga gli algoritmi di visione artificiale creati manualmente, risultando più adatti ad affrontare problemi complessi in cui la combinazione delle caratteristiche (per esempio, immagini, elaborazione linguistica e rilevamento di oggetti) non può essere realizzata facilmente dagli esperti umani.

Nonostante la netta superiorità (ma anche complessità) del deep learning, per le specifiche analitiche della videosorveglianza è quasi sempre sufficiente un algoritmo di machine learning classico, dedicato e ottimizzato: negli ambiti specifici può dare risultati simili a quelli di un algoritmo di deep learning eseguendo però meno operazioni matematiche e comportando di conseguenza minori costi (a livello di energia, addestramento, sviluppo, forza lavoro ecc.).
Raccolta, annotazione dei dati e addestramento
Per sviluppare un’applicazione analitica basata su AI è necessario raccogliere grandi quantità di dati. Per la videosorveglianza si tratta in genere di immagini e video di persone, veicoli o altri elementi ripresi dalle telecamere, che possono risultare d’interesse per l’analisi video. Tutti gli elementi pertinenti devono essere categorizzati ed etichettati attraverso un lavoro manuale lungo e impegnativo.
L’addestramento (apprendimento) è la fase in cui il modello riceve i dati annotati, utilizzando un framework per modificarsi e migliorarsi ciclicamente fino a ottenere la qualità desiderata e a risultare ottimizzato per svolgere il compito prestabilito. I metodi principali per l’apprendimento sono tre: supervisionato, non supervisionato, per rinforzo.
L’apprendimento supervisionato
L’apprendimento supervisionato (basato su esempi) è il metodo più utilizzato in ambito di machine learning. I dati di input sono già abbinati ai risultati di output desiderati (annotati) e le prestazioni dell’algoritmo addestrato dipendono direttamente dalla quantità e dalla qualità dei dati di addestramento. L’aspetto qualitativo più importante è utilizzare un set di dati che rappresenti tutti i potenziali dati di input in una situazione di utilizzo reale.
Solo se i dati di addestramento sono rappresentativi per il caso d’uso previsto, infatti, l’applicazione analitica finale sarà in grado di effettuare previsioni accurate anche quando elaborerà dati nuovi (cioè mai rilevati durante la fase di addestramento). Nel caso dei rilevatori di oggetti, lo sviluppatore deve quindi addestrare l’algoritmo con un’ampia varietà di immagini e con diversi esempi di oggetti, orientamenti, dimensioni, condizioni di illuminazione e sfondi.
L’apprendimento non supervisionato
L’apprendimento non supervisionato utilizza gli algoritmi per analizzare e raggruppare i set di dati non etichettati. Non si tratta di un metodo di addestramento comune nel settore della sorveglianza, perché il modello richiede molte calibrazioni e test, con risultati imprevedibili. I set di dati devono essere rilevanti per l’applicazione analitica, ma non etichettati né marcati chiaramente. Il lavoro di annotazione manuale viene quindi eliminato, ma il numero di immagini o video necessari per l’addestramento cresce considerevolmente.
L’apprendimento per rinforzo
Infine, l’apprendimento per rinforzo consiste nell’adottare misure idonee per una situazione specifica, aumentando al massimo il potenziale “premio” quando il modello compie le scelte giuste. L’algoritmo non utilizza le coppie dati/etichetta per l’addestramento, ma viene ottimizzato testandone le decisioni in una situazione di interazione con l’ambiente. L’apprendimento per rinforzo viene utilizzato nella robotica, nell’automazione industriale e nel planning strategico aziendale: dal momento che richiede feedback in grandi quantità, anch’esso viene raramente utilizzato nella videosorveglianza.
Terminata la fase di addestramento, il modello va testato accuratamente sul campo attraverso una procedura automatizzata teorica e pratica. Nella parte automatizzata, l’applicazione viene valutata utilizzando nuovi set di dati, non visti dal modello durante l’addestramento: se le valutazioni non corrispondono alle attese, il processo ricomincia dall’inizio, raccogliendo dati per l’apprendimento, effettuando/rifinendo le annotazioni e addestrando nuovamente il modello.
Raggiunto il livello qualitativo desiderato, si parte con i test sul campo: l’applicazione viene esposta a scenari reali, con quantità e variazioni di dati che dipendono dall’ambito di utilizzo previsto. Più l’ambito è ristretto, meno è necessario testare variazioni; per applicazioni più estese, occorrono invece più test. I risultati vengono poi nuovamente confrontati e valutati.
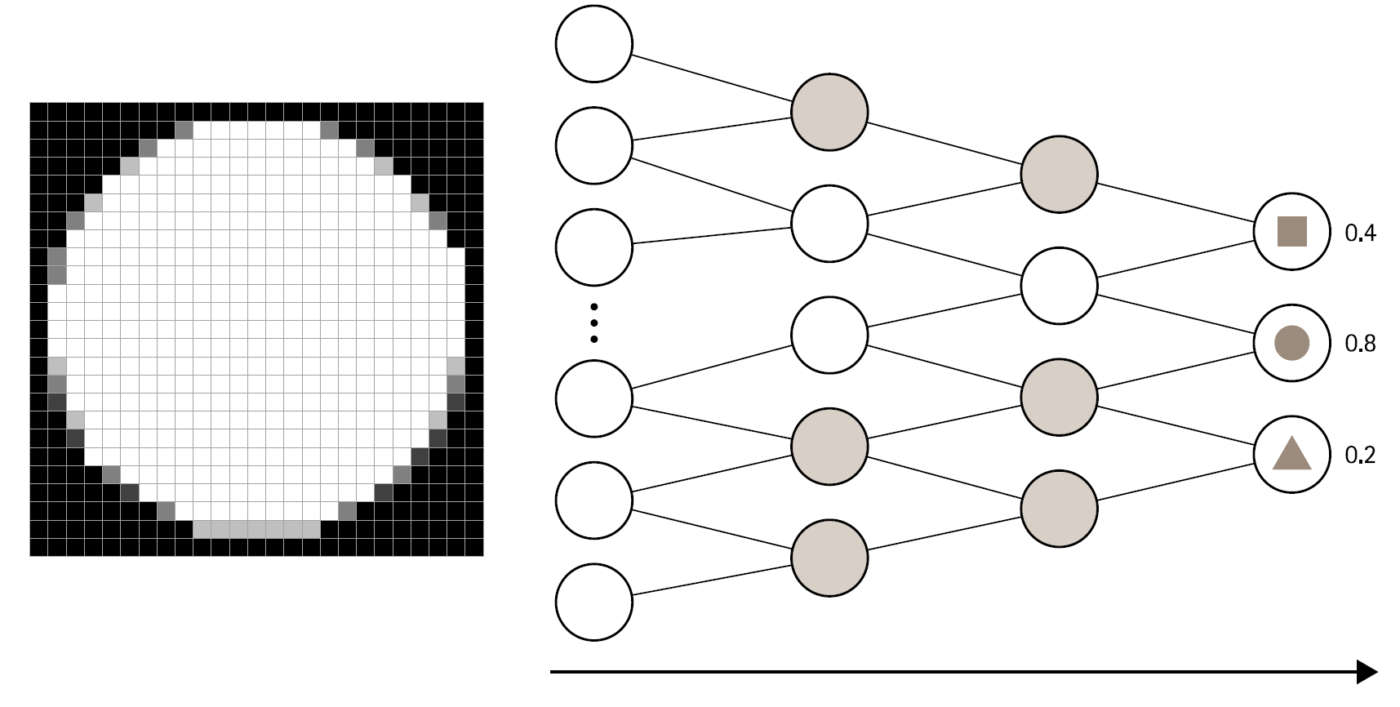
Implementazione del modello di machine learning addestrato
La fase di implementazione - anche detta fase di inferenza o predizione - consiste nel processo di esecuzione di un modello di machine learning addestrato. L’algoritmo utilizza quanto imparato durante la fase di apprendimento per produrre l’output desiderato a partire dalle scene reali catturate dalle telecamere.
Quando si esegue un algoritmo di machine learning su dati audio o video, per ottenere buone prestazioni in tempo reale, è necessario impiegare un acceleratore hardware specifico, di tipo edge-based (cioè integrato direttamente nelle telecamere di nuova generazione, con diversi vantaggi quali bassa latenza, bassi costi, esecuzione in tempo reale ecc.) o server-based (cioè supportato da dispositivi hardware esterni con processori GPU, MLPU, DLPU).
Un sistema ibrido “edge+server”, con pre-elaborazione sulla telecamera ed elaborazione successiva sul server, rappresenta spesso il perfetto punto di equilibrio tra costi e prestazioni, perché agevola la scalabilità delle applicazioni analitiche e riduce la potenza necessaria per lavorare sui diversi flussi delle telecamere.
L’importanza delle precondizioni
Per soddisfare le aspettative di qualità di un’applicazione analitica basata su AI, è fondamentale studiare le precondizioni e le limitazioni note, di solito riportate nella relativa documentazione. Ogni sistema di sorveglianza è unico e le prestazioni delle applicazioni devono essere valutate caso per caso.
La risoluzione delle immagini, il posizionamento delle telecamere e le condizioni ambientali di illuminazione sono solo alcuni dei fattori che determinano se effettivamente una ripresa può essere utilizzata per l’analisi video con AI. Per esempio, un elemento da prendere in considerazione è il caso d’uso: un video che sembra di buona qualità agli occhi di un operatore potrebbe non avere una qualità ottimale per le prestazioni di un’applicazione video-analitica. Molti metodi di elaborazione dell’immagine comunemente utilizzati per rendere il video più gradevole all’occhio (noise reduction, WDR, auto IRIS ecc.) possono infatti risultare controproducenti in fase di analisi.
È sufficiente pensare ai sistemi di illuminazione IR: sebbene utili per distinguere persone, oggetti e movimenti al buio, risultano meno efficaci rispetto a un’adeguata illuminazione ambientale in presenza di condizioni meteo critiche (pioggia, neve, nebbia), impedendo una corretta analisi quando i raggi IR colpiscono direttamente uno o più elementi della scena.
Per l’analisi video con AI, sono altrettanto importanti la distanza di rilevamento e la velocità di movimento. L’applicazione dev’essere in grado di “vedere” bene l’oggetto per un periodo di tempo sufficientemente lungo, la cui durata dipende dalle capacità di elaborazione della piattaforma (frame rate): minori sono le capacità di elaborazione, più l’oggetto dev’essere visibile per essere rilevato. Inoltre, se il tempo di esposizione della telecamera non è idoneo alla velocità dell’oggetto, anche la sfocatura da movimento che appare sull’immagine può ridurre la precisione di rilevamento.
In genere, una telecamera con risoluzione molto elevata non assicura una maggiore distanza di rilevamento, mentre le capacità di calcolo necessarie per eseguire un algoritmo di machine learning sono proporzionali alle dimensioni dei dati di input (per esempio quattro volte per la risoluzione 4K rispetto al Full HD). Per via delle limitate capacità di calcolo di molti dispositivi, è consigliabile eseguire le applicazioni AI a una risoluzione inferiore rispetto a quella nativa oppure limitandosi a una porzione dell’immagine (crop).
Il vantaggio di una visione instancabile
Nel realizzare un programma per la visione artificiale, il vantaggio dell’intelligenza artificiale rispetto alla programmazione tradizionale consiste nella possibilità di elaborare grandi quantità di dati, senza correre il rischio di perdere la concentrazione e ridurre le performance operative. Un programmatore in carne e ossa, infatti, prima o poi si stanca e perde la concentrazione durante la visione delle riprese, commettendo molto probabilmente qualche errore.
FONDE DELL'ARTICOLO : New Business Media Srl